搭建IntelliJ+Maven的Hadoop开发环境
Hadoop开发中需要用到至少不下10个的依赖包,它们相互间的依赖关系比较复杂,不同版本的依赖关系也有所不同,而间接依赖导致的程序错误并不会在运行之前报错,因此确定适合一个版本的依赖包,会耗费相当多的时间。Maven是一个依赖管理和项目构建的工具,它利用惯例组织Java项目的结构,并允许通过简单的配置定义直接依赖,而直接依赖所需的其他依赖则会通过事先定义好的关系列表自动下载,大大节省了开发者本身的工作量。
使用Maven管理依赖,相比于下载到lib文件夹再导入项目,有以下优势:
- 节省找寻合适依赖所需的时间
- 便于依赖升级以适配不同的Hadoop版本
- 依赖下载到本地库后可重复使用
- 缩小版本管理的文件体积
Maven在主流的Java IDE上都有插件,Eclipse可通过安装m2eclipse,但这里个人推荐与智能化程度更高、联网更迅速、体验更流畅的IntelliJ IDEA配合,以下就简要介绍IntelliJ IDEA如何使用Maven。(以IntelliJ IDEA 13为例,它自带了Maven的支持,无需安装插件)
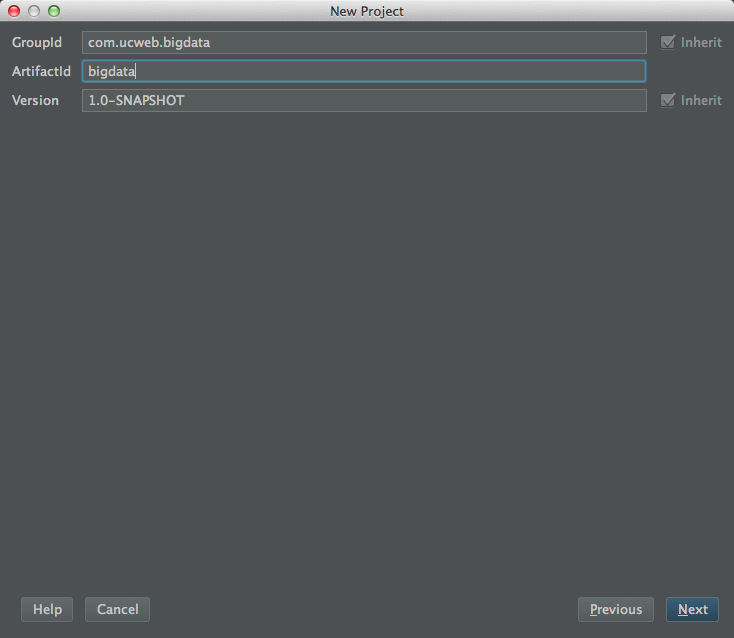
New Project -> Maven新建一个Maven项目,在属性栏填写GroupId(项目或组织的唯一标识)和ArtifactId(项目的通用名称):![]()
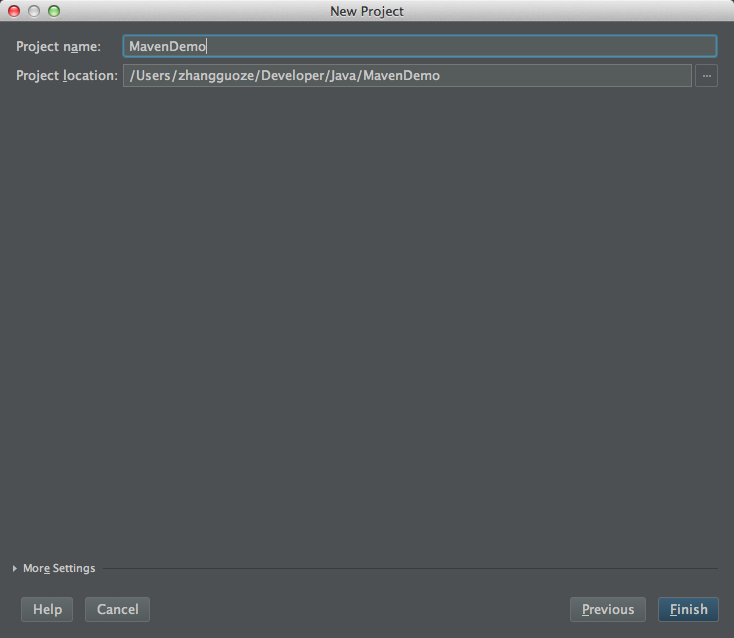
- Next之后填写项目名和项目位置:
![]()
- 新建项目之后有弹窗提示,选择自动导入:
![]()
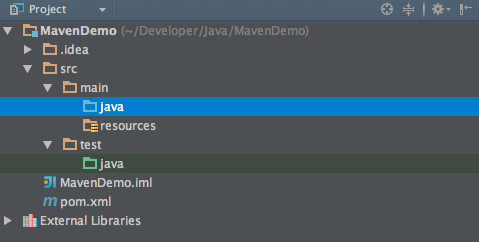
- 项目生成后的架构是这样的,我们在src/main/java路径下写项目代码,pom.xml是项目统一的配置文件。
![]()
- 因为我们线上用的是Cloudera的Hadoop版本,所以我们需要在pom.xml的project节点下添加一个CDH5的Maven远程依赖仓库(参考Using the CDH 5 Maven Repository)
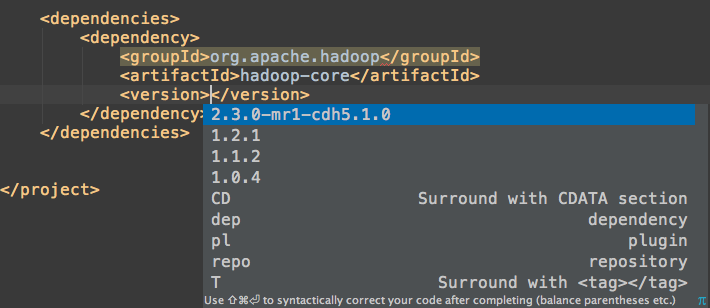
- 开发一个普通的Hadoop项目,我们一般需要hadoop-common、hadoop-core两组依赖;如果需要读取HDFS上的文件内容,则需要hadoop-hdfs和hadoop-client另外两组依赖;如果需要读取HBase的数据,则需要再加入hbase-client。(以上均为artifactId,以CDH5.1.0为例)
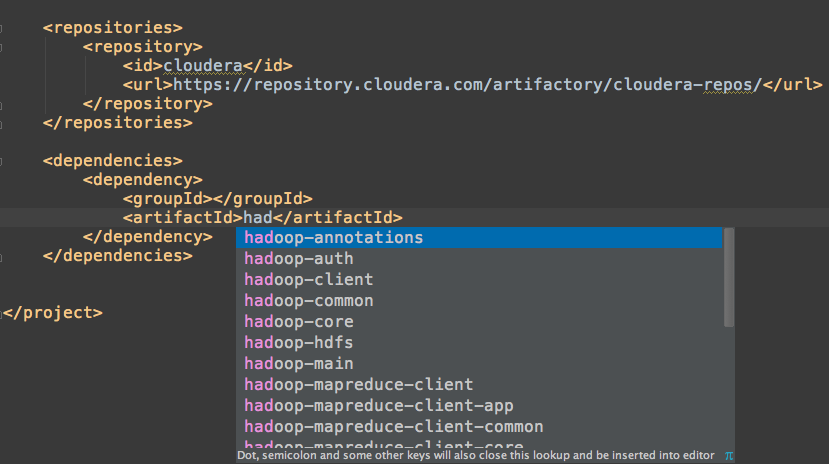
- IntelliJ IDEA提供了对pom文件非常智能的自动补全和实时查询功能:
![]()
![]()
- Let’s Hadoop!