逻辑回归碎碎念
sigmoid函数
逻辑回归(Logistic-Regression)是数据挖掘领域的一种基本的回归和分类算法。很长的一段时间里我对逻辑回归的理解仅限于「有逻辑的回归」。直到有次面试一个实习生,跟他聊起正在做的热门电台排行榜,需要把各个指标加权得出的分值映射到(0,1)空间,采用的是最简陋的线性映射方法。他建议我可以用sigmoid函数做,我立时两眼放光,请教起sigmoid函数相对于线性映射的好处。他的回答是「sigmoid函数没有不可导的点」,当时我为自己的无知感到窘迫,就没敢再问下去。直到后来系统地阅读数据挖掘的书,才发现他没有说对。sigmoid函数最显著优于线性映射的地方,是实现了经济学上经常用吃饼类比的边际递减效用,能够避免概率的分布被少数的噪点破坏。
再回到回归这个问题上,数据挖掘领域讲的回归,是通过对已知样本进行训练,再对未知样本预测score的过程。逻辑回归正是把线性回归通过sigmoid函数映射到(0,1)空间而形成的。而score反映到逻辑回归上,是一个概率值。于是逻辑回归广泛用于预测类似问题:中国队能不能冲进世界杯?文章会不会和马伊琍离婚?莫言获得诺贝尔文学奖的概率是多少?而回归问题只需要设置一个概率的阈值,就可以进一步演变成分类问题。
ROC和AUC
通常对离线模型的评估可能有多个指标,比如准确率、召回率或者F-Score(准确率和召回率的乘积),但是这些都没有包含预测值的排序信息。设想这样的一种场景,我构建了一个判断人有没有钱的二元分类器,可光知道一个人有没有钱是不够的,我还希望找到最有钱的那几个人,和他们交交朋友。那么对于我们这样一个分类器的场景来说,把最高分值的那几个样本分错显然是更恶劣的,而不是每个样本的正确率都是同等重要的,因此我们需要一个能考虑位置信息的评价指标。AUC也就这样应运而生。
AUC表达的是,你随机挑选一个正样本和一个负样本,通过离线模型输出的score,正样本大于负样本的概率。直觉上我们可以知道,把一个负样本判断为0.6(假设阈值取0.5),会比把一个负样本判断为0.9,AUC的值要更高些。而如果所有的正样本score都高于0.5,负样本score都低于0.5,那么AUC的值就是1,反之是则0。
但通过每次枚举一个正样本和负样本的方式来计算AUC显然太慢了,更好的方法是计算ROC曲线的线下面积(已被证实等于AUC的值)。ROC是一条起于(0,0)终于(1,1)的曲线,横轴和纵轴分别代表假正率(意为负样本被识别为正的比例)和真正率(意为正样本被识别出来的比例)。这条曲线越靠近左上角点,AUC的值越高,而如果ROC低于斜对角线,就说明离线模型的性能比完全随机还差(**Oh No!**)。
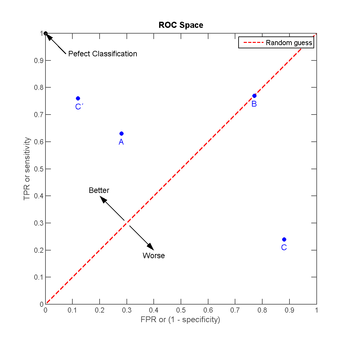
ROC的绘制过程可参考:ROC曲线绘制与AUC计算
特征筛选和多元共线性
这是两种会影响回归效果的Bad Case:
- 某个特征其实与最终的score判断关系不大
- 多个特征之间强相关,其实只要一个就够了
解决的办法都是去掉一些特征,重新建模。这方面最常用的是逐步回归:逐个引入自变量,每次引入都检验原先所有自变量的显著性,一旦发现低于阈值的就先剔除;这样反复进行直到没有不显著的自变量被包含,也没有显著的自变量被剔除。